Circle and Points 解説
- 問題名:Circle and Points (PKU)
- 出典:Problem D, ACM/ICPC Japan Domestic, 2004-07-02
- 難易度:☆☆☆
- 問題の種類:幾何
- 解法:2点を円周上に持つ円を調べる
- 解答ソースコード:
- 1981-deq_1a.cpp(通常の解法,double型で直接計算,PKUはTLE)
- 1981-deq_1b.cpp(通常の解法,complexを使用したベクトル演算,PKUはTLE)
- 1981-deq_2.cpp(分割統治法)
- プログラムプロムナードの解説:2004年11月号『点の密集区域』(石畑 清)
「半径 1 の円で囲める点の最大数を求める」という,幾何問題の中では簡単な部類の問題です。 この問題には,通常の解法(想定解)「2点を円周上に持つ円を調べる」の他に,分割統治法による解法があります。 プログラムプロムナードの解説が非常に詳しいのでそちらの解説もぜひ読んでみてください。
2点を円周上に持つ円を調べる
アルゴリズムの概略
点を囲む円は色々と考えられますが,この場合は「2点を円周上に持つような円」だけを考えればOKです。 というのも,最も多く点を囲む円があったとして, 囲む点の数を減らさずに,囲んでいる中の2点が円周上に来るように動かすことが可能だからです。
そこで,円周上に2点を持つような円を作れるような2点を選べば(2点間の距離が「半径×2」以下であれば必ず作れます), そのような円を求めることができ(下図のように2つ存在します), 後はその円の中に含まれる点の数を数え上げればOKです。
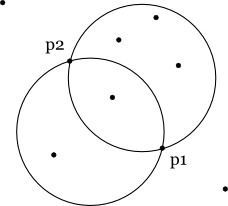
もし2点を円周上に持つような円が作れなければ,囲える点の数は1つになります(点の数は 1 <= N なので)。
次に,そのような2つの円を具体的に求める手順を考えましょう。 円を求めるというのは,その中心点と半径を求めることです。 とはいっても,この問題では半径は 1 なので,中心点を求めることになります。 ここで簡単な幾何の知識が必要になってきます。
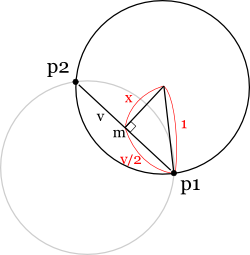
まず p1 と p2 の中点 m を求め,そこから線分(p1, p2)に垂直な方向に x だけ移動した点が円の中心点になります。 図を見て分かる通り,x はピタゴラスの定理(三平方の定理)より,
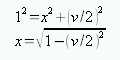
で求まります。 線分(p1, p2)の単位法線ベクトル(線分(p1, p2)に対して垂直でかつ長さが1の線分)にこの値 x を掛けたものを m に足せば円の中心点が求まるわけです。
アルゴリズムの計算量
このアルゴリズムの計算量は,まず2点をピックアップするのに二重ループを回すので O(n2) が必要です。 その中で円を2つ作り,それぞれの円に対して各点が中にあるかどうかのループを回すので,その部分は 2×O(n) です。 結局,計算量のオーダーは O(n3) になります。 n = 300 なので,最悪の場合 2×3003 = 54,000,000 です。 幾何計算が入るので係数は大きそうですが,1つのデータセットに対して現実時間内で終了しそうです。
アルゴリズムの実装
幾何問題の実装には,直接double型の値をいじる方法と,C++ STLのcomplex型を使ってベクトル演算を行う方法があります。 前者は方程式を解いて座標などを求める場合によく使い,後者のベクトル演算は問題をベクトルで考えて解く場合に簡単に記述できます。
基本的にはベクトルの足し算掛け算などで考えて解いて,必要があれば方程式を立てて解くのが楽だと思います。 そこで,ぜひベクトル演算の基礎を学んでおいてください(平面幾何におけるベクトル演算)。
幾何問題における基本的な注意点を2つ挙げます。 一つは誤差の取り扱いです。 浮動小数点の計算では必ず計算誤差が生じるので,数値の比較(=, <, >)には細心の注意を払ってください。 もう一つは平方根を取ること,つまり sqrt は遅いということです。 距離の計算には必ず付き物の sqrt ですが,比較だけであれば sqrt が必要ないこともしばしばあります(例えば今回のような円の内外判定)。 sqrt を外すだけで10倍ほど速くなることもあるので,無用な sqrt は避けるようにしましょう。
分割統治法
アルゴリズムの概略
これはプログラムプロムナードの『点の密集区域』で解説されている方法です。 確かに画像処理ではよく使われる方法の一つで,この幾何問題も分割統治法で解くことができます。
詳細は上記リンク先(PDF文書)の解説に譲るとして,重要な点をいくつか挙げておきます(先にプログラムプロムナードの解説を読んでね)。
まず,この解法はつまるところ「greedyな枝刈り探索」です。 筆者自身が全探索では遅すぎたと述べています。 つまり,この解法は全探索では遅すぎて使い物にならず,計算量を推定できない(見切り発車しかできない)枝刈り探索を行わなければならないということです。 ICPC的にはかなり適用が難しい解法といえますが,いざというときのために懐に忍ばせておくとよいでしょう。
ここで「greedyな枝刈り探索」というのは,つまり (1) 優先度付き待ち行列を使い, (2) 最もよさそうなところから(greedyに)探索することにより,枝刈りを効果的にしているということです*1。 この手法は分割統治法とは関係なく,探索問題でよく使われるので覚えておきましょう。
アルゴリズムの計算量
不明です。
アルゴリズムの実装
C++の場合は priority_queue を使って優先度待ち行列を実装すると良いでしょう。 STLに慣れていない方は 1981-deq_2.cpp を参考にしてみてください。
補足1: 単純に「greedy探索」といえば, 最もよさそうなところ以外は探索しない(つまり最適解が見つかるとは限らない)方法を指します。 ここでは最もよさそうなところから探索するだけで,全探索と同じように最適解が見つかる方法なので少し意味が違います。 ただし,探索問題におけるgreedyな(欲張りな)という形容詞の基本的な意味は一緒です。
$Id: index.shtml 1335 2007-03-01 09:06:39Z SYSTEM $